最近在学习28377双核IPC,目的是想在两个CPU之间交互10个16bit数据,想在特定时刻一次性交互完。但是看ti提供的例程后一头雾水,不知道如何操作,发现不论是IPC dirver还是IPC lite driver,提供的函数都比较简单,都是写一个数或者读一个数。使用IO翻转简单测试了下双核IPC dirver交互一次的时间,发现读一个数要500ns左右,为了这一个数来回交互,每个CPU都开两个中断,还耗费500ns,感觉好麻烦啊。例程里倒是有BlockRead,BlockWrite的函数,但是基于共享内存GS0~GS15区块的,读写时两个CPU还得互换共享内存的控制权,感觉也不太实用,时间没测,但是我觉得交换内存控制权了,时间一定短不了。
我的问题是:
1,如果我想交互10字节数据,如何操作?难道要把IPCLtoRDataWrite()或者IPCLtoRDataRead()函数循环运行10遍?这样带来的问题是,根据我测试的时间,IPC读写一个数要500ns,那么传10个数就要5us,这样对于标榜实时控制的系统,尤其是电流环控制是否太长?有没有什么高效率的方法?
2 BlockWrite/Read的问题。cpu01_to_cpu02_ipcdrivers例程里倒是有BlockRead,BlockWrite的函数,该例程定义了一个地址CPU02TOCPU01_PASSMSG 0x0003FBF4,使用该地址进行数据中转。但是我有个疑问,CPU1和CPU2之间的Message Ram定义如下:
CPU2TOCPU1RAM : origin = 0x03F800, length = 0x000400
CPU1TOCPU2RAM : origin = 0x03FC00, length = 0x000400
0x0003FBF4这个地址在CPU2TOCPU1RAM很靠后的部位了,按照例程中提供的操作,利用IPCLtoRBlockWrite()函数写256个数到CPU2,0x0003FBF4指向目标数组的起始地址,但是0x0003FBF4+256=0x0003FCF4,地址已经溢出了,已经跑到了CPU1TOCPU2RAM的空间去了,这是不是有问题?还是我理解错了?所有的数据都是通过0x0003FBF4这一个地址进行中转,而不是在messageRAM中开了一个0x0003FBF4+256的缓冲区?但是这样也太傻了吧。。。
并且按照说明,BlockWrite/Read只能使用共享内存GS0-GS15,也就是我想从CPU1往CPU2写数,必须先把CPU1的数据搬到GS0~GS15共享RAM中,然后才能写到CPU2的一个地址?
3关于例程,每个例程都提供了两个工程cpu01_to_cpu02_ipcdrivers_cpu01/cpu02和cpu02_to_cpu01_ipcdrivers_cpu01/02,我在做自己的工程的时候到底该参考哪个?还是必须把这俩工程都融入到我自己的程序中去?我是不是可以理解为这两个工程就是谁做主控的差别。我在建立我自己工程的IPC通信的时候,只用选择一个CPU做主就行,比如我选定CPU1做主,只用参考cpu01_to_cpu02_ipcdrivers例程就行,读写操作都由CPU1来控制,这样就够了,不用再去管CPU2往CPU1写数的程序?
也就是说我的IPC通信构架应该是下面的哪种:
第一种 :cpu1 write data to cpu2 / cpu1 read data from cpu2
第二种: cpu1 write data to cpu2 / cpu2 write data to cpu1
第三种: cpu1 read data from cpu2 / cpu2 read data from cpu1
第四种: cpu2 write data to cpu1 / cpu2 read data from cpu1
其中第一种对应cpu01_to_cpu02_ipcdrivers,第四种对应cpu02_to_cpu01_ipcdrivers,第二种和第三种是我想出来的,例程里没有。是不是我只需要在一和四里面选一种就够了?一般肯定是选一,就是CPU1做主控
暂时先提问这些,盼复
Young Hu:
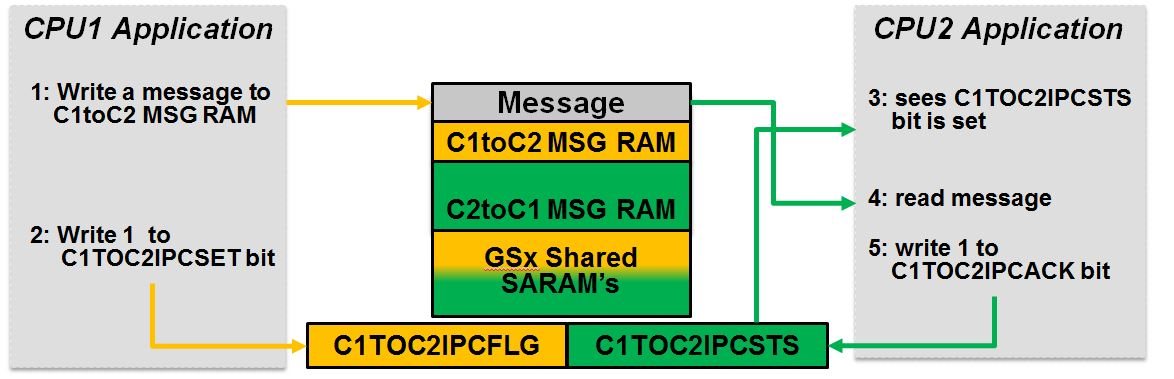
可以参考下面的例子自己做一个架构
Basic option – no software drivers needed and easy to use!
Use the message SARAM’s and global shared SARAM’s (GSx blocks) to pass data between processors at a known address
Use the IPC flag registers to tell the other processor that the data is ready
最近在学习28377双核IPC,目的是想在两个CPU之间交互10个16bit数据,想在特定时刻一次性交互完。但是看ti提供的例程后一头雾水,不知道如何操作,发现不论是IPC dirver还是IPC lite driver,提供的函数都比较简单,都是写一个数或者读一个数。使用IO翻转简单测试了下双核IPC dirver交互一次的时间,发现读一个数要500ns左右,为了这一个数来回交互,每个CPU都开两个中断,还耗费500ns,感觉好麻烦啊。例程里倒是有BlockRead,BlockWrite的函数,但是基于共享内存GS0~GS15区块的,读写时两个CPU还得互换共享内存的控制权,感觉也不太实用,时间没测,但是我觉得交换内存控制权了,时间一定短不了。
我的问题是:
1,如果我想交互10字节数据,如何操作?难道要把IPCLtoRDataWrite()或者IPCLtoRDataRead()函数循环运行10遍?这样带来的问题是,根据我测试的时间,IPC读写一个数要500ns,那么传10个数就要5us,这样对于标榜实时控制的系统,尤其是电流环控制是否太长?有没有什么高效率的方法?
2 BlockWrite/Read的问题。cpu01_to_cpu02_ipcdrivers例程里倒是有BlockRead,BlockWrite的函数,该例程定义了一个地址CPU02TOCPU01_PASSMSG 0x0003FBF4,使用该地址进行数据中转。但是我有个疑问,CPU1和CPU2之间的Message Ram定义如下:
CPU2TOCPU1RAM : origin = 0x03F800, length = 0x000400
CPU1TOCPU2RAM : origin = 0x03FC00, length = 0x000400
0x0003FBF4这个地址在CPU2TOCPU1RAM很靠后的部位了,按照例程中提供的操作,利用IPCLtoRBlockWrite()函数写256个数到CPU2,0x0003FBF4指向目标数组的起始地址,但是0x0003FBF4+256=0x0003FCF4,地址已经溢出了,已经跑到了CPU1TOCPU2RAM的空间去了,这是不是有问题?还是我理解错了?所有的数据都是通过0x0003FBF4这一个地址进行中转,而不是在messageRAM中开了一个0x0003FBF4+256的缓冲区?但是这样也太傻了吧。。。
并且按照说明,BlockWrite/Read只能使用共享内存GS0-GS15,也就是我想从CPU1往CPU2写数,必须先把CPU1的数据搬到GS0~GS15共享RAM中,然后才能写到CPU2的一个地址?
3关于例程,每个例程都提供了两个工程cpu01_to_cpu02_ipcdrivers_cpu01/cpu02和cpu02_to_cpu01_ipcdrivers_cpu01/02,我在做自己的工程的时候到底该参考哪个?还是必须把这俩工程都融入到我自己的程序中去?我是不是可以理解为这两个工程就是谁做主控的差别。我在建立我自己工程的IPC通信的时候,只用选择一个CPU做主就行,比如我选定CPU1做主,只用参考cpu01_to_cpu02_ipcdrivers例程就行,读写操作都由CPU1来控制,这样就够了,不用再去管CPU2往CPU1写数的程序?
也就是说我的IPC通信构架应该是下面的哪种:
第一种 :cpu1 write data to cpu2 / cpu1 read data from cpu2
第二种: cpu1 write data to cpu2 / cpu2 write data to cpu1
第三种: cpu1 read data from cpu2 / cpu2 read data from cpu1
第四种: cpu2 write data to cpu1 / cpu2 read data from cpu1
其中第一种对应cpu01_to_cpu02_ipcdrivers,第四种对应cpu02_to_cpu01_ipcdrivers,第二种和第三种是我想出来的,例程里没有。是不是我只需要在一和四里面选一种就够了?一般肯定是选一,就是CPU1做主控
暂时先提问这些,盼复
BIN YAO1:我这边是通过IPC中断,在GS0~GS15中交互数据,事先划分好控制权,比如CPU1写给CPU2的就在GS0里,CPU2返回CPU1的就在GS1里这样





