不是手动搬移某个函数,而是将所有代码都放到ram运行。
10#:
.text: LOAD = FLASHX, RUN = RAMX, LOAD_START(_RamfuncsLoadStart), LOAD_SIZE(_RamfuncsLoadSize), LOAD_END(_RamfuncsLoadEnd), RUN_START(_RamfuncsRunStart), RUN_SIZE(_RamfuncsRunSize), RUN_END(_RamfuncsRunEnd), PAGE = 0
自己定义FLASHX为整个FLASH,RAMX为所有RAM,在运行时进行搬运。
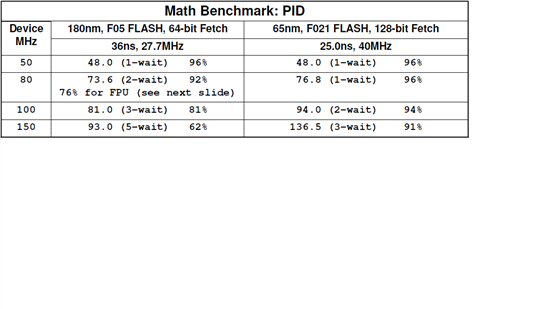
实际上我不确定你为什么要这样做,因为如果仅仅是为了速度快的原因,这样做已经没有什么意义了,相比早期的F28335或者F2812之类的芯片,因为F28377D的FLASH采用最新的65nm工艺,FLASH上运行代码的速度已经跟RAM上基本没有差别了。
下面给出的是对于控制最常见的PID算法,在相同运行频率下,使用65nm工艺的F28377D相比使用180nm工艺的F2812或者F28335等芯片的FLASH相比RAM的实际运算速度。供参考。